A
A
A
A
A
A
The
The
A
a
A
A
A
A
A
A
Abstract
Generating text-editable and pose-controllable character videos have an imperious demand in creating various digital human. Nevertheless, this task has been restricted by the absence of a comprehensive dataset featuring paired video-pose captions and the generative prior models for videos. In this work, we design a novel two-stage training scheme that can utilize easily obtained datasets (i.e.,image pose pair and pose-free video) and the pre-trained text-to-image (T2I) model to obtain the pose-controllable character videos. Specifically, in the first stage, only the keypoint-image pairs are used only for a controllable text-to-image generation. We learn a zero-initialized convolu- tional encoder to encode the pose information. In the second stage, we finetune the motion of the above network via a pose-free video dataset by adding the learnable temporal self-attention and reformed cross-frame self-attention blocks. Powered by our new designs, our method successfully generates continuously pose-controllable character videos while keeps the editing and concept composition ability of the pre-trained T2I model. The code and models will be made publicly available.
Pipeline
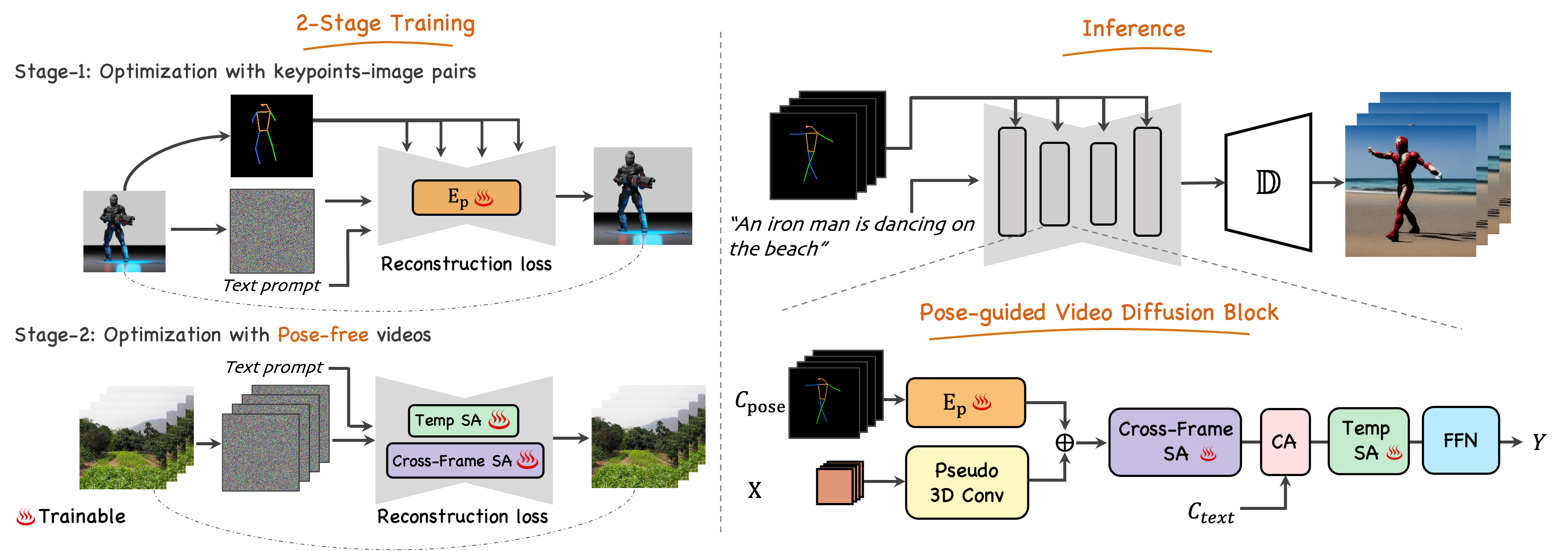
Video Generation Using Stable Diffusion
The
A
A
A
A
A
A
A
A
A
A
A
A
A
A
A
A
A
A
A
A
A
BibTeX
@article{ma2023follow,
title={Follow Your Pose: Pose-Guided Text-to-Video Generation using Pose-Free Videos},
author={Ma, Yue and He, Yingqing and Cun, Xiaodong and Wang, Xintao and Shan, Ying and Li, Xiu and Chen, Qifeng},
journal={arXiv preprint arXiv:2304.01186},
year={2023}
}